Основные понятия и терминология Web
Каждый из вас ежедневно пользуется браузером на своем компьютере, телефоне, ноутбуке и т.д.
Вы, не задумываясь, вводите нужный адрес и получаете интересующую Вас информацию.
- Но что при этом происходит? 🤔
- Как браузер понимает, откуда брать информацию? 🤔
- Кого он спрашивает? 🤔
- Как помнит ваше имя? 🤔
Вы, наверняка, слышали, что сайты «хранятся на серверах», откуда мы их и получаем. Далее мы рассмотрим:
- Как браузер ищет сервер, на котором «лежит» сайт.
- Как происходит общение между сервером и браузером.
Эти знания понадобятся Вам в дальнейшем при разработке Ваших первых сайтов.Вы должны понимать, что Вы пишете, как это будет отображаться и передаваться клиентам.Более того эти знания необходимы для обеспечения безопасности Ваши продуктов, так как лазейки для хакеров могут найтись в самых неожиданных моментах.
URI
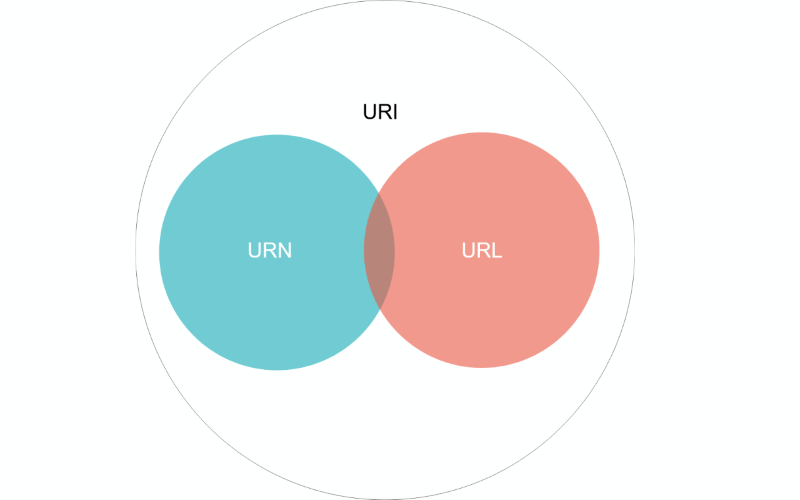
URI — это символьная строка, позволяющая идентифицировать какой-либо ресурс: документ, изображение, файл, службу, ящик электронной почты и т. д. Прежде всего, речь идёт, конечно, о ресурсах сети Интернет и Всемирной паутины. URI предоставляет простой и расширяемый способ идентификации ресурсов. Расширяемость URI означает, что уже существуют несколько схем идентификации внутри URI, и ещё больше будет создано в будущем.
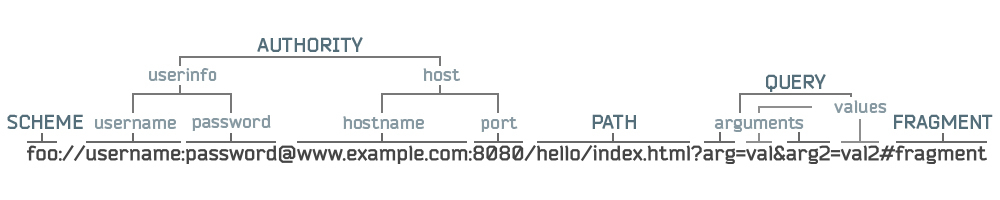
URI строится по определенным правилам и состоит из обязательных схемы и иерархической части, а также опциональных запросов (ему предшествует знак "?") и фрагмента (ему предшествует знак "#"). Иерархическая часть в свою очередь состоит из необязательного Authority и обязательного пути. Authority включает в себя Userinfo (логин и пароль), хост и порт. Кроме того, путь может содержать так называемые параметры. Параметры используются не часто.
На схеме это выглядит вот так:
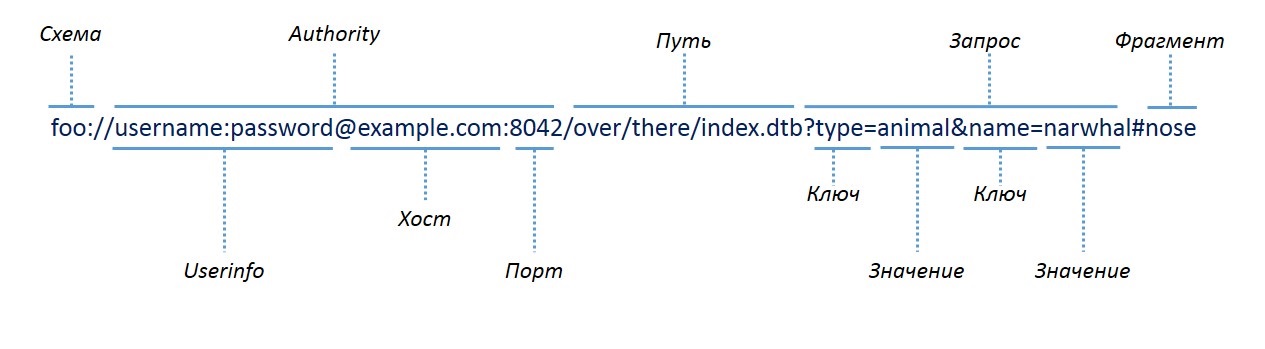
 Пример URI:
Пример URI:
URL
URL — это URI, который, помимо идентификации ресурса, предоставляет ещё и информацию о местонахождении этого ресурса. URL описывается в RFC 1738 (December 1994, Xerox Corporation, T. Berners-Lee). В этом RFC указаны описаны различные схемы для протоколов ftp, http, nntp и т.д.
Поскольку URL — это частный случай URI, схема в общем случае выглядит точно так же, однако для разных протоколов актуальны те или иные ее части. Например, для протокола http, схема URL выглядит следующим образом:

URN
URN — это URI, который только идентифицирует ресурс в определённом пространстве имён (и, соответственно, в определённом контексте), но не указывает его местонахождения. Например, URN urn:ISBN:0-395-36341-1 — это URI, который указывает на ресурс (книгу) 0-395-36341-1 в пространстве имён ISBN, но, в отличие от URL, URN не указывает на местонахождение этого ресурса: в нём не сказано, в каком магазине её можно купить, или на каком сайте скачать. Впрочем, в последнее время появилась тенденция говорить просто URI о любой строке-идентификаторе, без дальнейших уточнений. Так что, возможно, термины URL и URN скоро уйдут в прошлое.

DNS
Для адресации узлов Интернета используются специальные числовые «коды» – IP-адреса.
Система доменных имён как раз служит для выполнения преобразований между символьными и числовыми адресами.
Традиционный IP-адрес может быть записан с помощью четырех чисел в десятичной системе счисления, например: 192.168.175.13 или 194.85.92.93.
DNS позволяет сопоставить числовой IP-адрес и символьный, например: 194.85.92.93 = test.ru.
Вы можете узнать ip-адрес узла воспользовавшись командой ping domain_name в командной строке.

При этом символьный адрес в DNS представляет собой текстовую строку, составленную по особым правилам. Самое важное из этих правил – иерархия доменов. Система адресов DNS имеет древовидную структуру. Узлы этой структуры называются доменами. Каждый домен может содержать множество «подчиненных» доменов. Дерево DNS принято делить по уровням: первый, второй, третий и так далее. При этом начинается система с единственного корневого домена (нулевой уровень).
Адреса с использованием DNS записываются в виде последовательности, отражающей иерархию имен. Чем «выше» уровень домена, тем правее он записывается в строке адреса. Разделяются домены точками. Разберем, например, строку www.site.nic.ua. Здесь домен www – это домен четвертого уровня, а другие упомянутые в этой строке домены расположены в домене первого уровня UA. Например, site.nic.ua – это домен третьего уровня.
Важно
Очень важно понимать, что привычный адрес веб-сайта, скажем, www.test.ua, обозначает домен третьего уровня (www), расположенный внутри домена второго уровня test.ua.
Для преобразования имен доменов и IP-адресов в DNS используется распределенная система из специальных серверов. Каждый из серверов обслуживает свой «набор клиентов», выполняя для них преобразования адресов. Среди серверов DNS существует иерархия «доверия» и распределение «зон ответственности»: тот или иной сервер может отвечать за определенный набор доменов. При этом DNS-серверы, входящие в глобальную систему DNS Интернета, связаны между собой и обмениваются информацией по достаточно сложным протоколам. Например, между серверами передаются данные об изменении адресации в той или иной доменной зоне. Все это направлено на обеспечение успешного преобразования всех адресов, входящих в DNS, по запросу от любого компьютера, подключенного к Интернету, где бы этот компьютер ни находился.
Наиболее важны так называемые корневые серверы DNS, обеспечивающие работу всей системы доменных имен Интернета в целом. Существует 13 таких серверов, и они принадлежат техническому центру ICANN. Ключевую роль играют также корневые серверы доменов первого уровня (например, UA), обеспечивающие распространение по всему Интернету DNS-информации о домене, находящемся в их зоне ответственности.
С точки зрения пользователя и в сильно упрощенном виде алгоритм работы DNS по поиску адресов web-сайтов можно описать следующим образом. Когда пользователь вводит в адресной строке браузера адрес web-сайта, например, site.nic.ua, компьютер выполняет запрос к тому или иному известному этому компьютеру серверу DNS, «спрашивая» сервер о том, какой IP-адрес связан с «доменным адресом», указанным пользователем. В ответ сервер DNS, проверив соответствие по своим внутренним таблицам или выполнив запрос к другим серверам DNS, присылает искомый IP-адрес. Далее браузер устанавливает соединение с web-сайтом уже по IP-адресу.
HTTP
HTTP (HyperText Transfer Protocol — протокол передачи гипертекста) — символьно-ориентированный клиент-серверный протокол прикладного уровня без сохранения состояния, используемый сервисом World Wide Web. Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier – уникальный идентификатор ресурса) в запросе клиента. Основными ресурсами являются хранящиеся на сервере файлы, но ими могут быть и другие логические (напр. каталог на сервере) или абстрактные объекты (напр. ISBN). Протокол HTTP позволяет указать способ представления (кодирования) одного и того же ресурса по различным параметрам: mime-типу, языку и т. д. Благодаря этой возможности клиент и веб-сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
Структура протокола HTTP
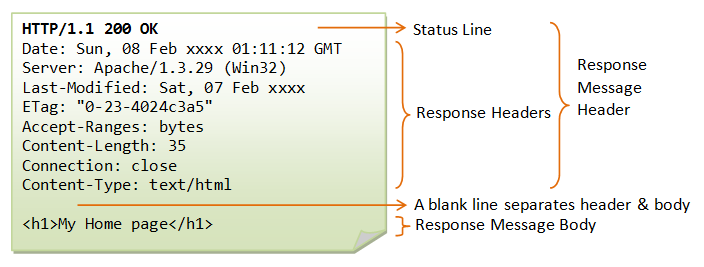
Структура протокола определяет, что каждое HTTP-сообщение состоит из трёх частей, которые передаются в следующем порядке:
- Стартовая строка (англ. Starting line) — определяет тип сообщения;
- Заголовки (англ. Headers) — характеризуют тело сообщения, параметры передачи и прочие сведения;
- Тело сообщения (англ. Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
Стартовая строка HTTP
Стартовая строка является обязательным элементом, так как указывает на тип запроса/ответа, заголовки и тело сообщения могут отсутствовать.
Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
Метод URI HTTP/Версия протокола
Пример запроса:
1GET /web-programming/index.html HTTP/1.1
Стартовая строка ответа сервера имеет следующий формат:
HTTP/Версия КодСостояния
Например, на предыдущий наш запрос клиентом данной страницы сервер ответил строкой:
HTTP/1.1 200 Ok
Методы протокола HTTP
Метод HTTP (англ. HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами. Названия метода чувствительны к регистру.
OPTIONS
Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. Предполагается, что запрос клиента может содержать тело сообщения для указания интересующих его сведений. Формат тела и порядок работы с ним в настоящий момент не определён. Сервер пока должен его игнорировать. Аналогичная ситуация и с телом в ответе сервера. Для того чтобы узнать возможности всего сервера, клиент должен указать в URI звёздочку — «». Запросы «OPTIONS HTTP/1.1» могут также применяться для проверки работоспособности сервера (аналогично «пингованию») и тестирования на предмет поддержки сервером протокола HTTP версии 1.1. Результат выполнения этого метода не кэшируется.
GET
Используется для запроса содержимого указанного ресурса. С помощью метода GET можно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса. Клиент может передавать параметры выполнения запроса в URI целевого ресурса после символа «?»: GET /path/resource?param1=value1¶m2=value2 HTTP/1.1 Согласно стандарту HTTP, запросы типа GET считаются идемпотентными — многократное повторение одного и того же запроса GET должно приводить к одинаковым результатам (при условии, что сам ресурс не изменился за время между запросами). Это позволяет кэшировать ответы на запросы GET. Кроме обычного метода GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовки If-Modified-Since, If-Match, If-Range и подобные. Частичные GET содержат в запросе Range. Порядок выполнения подобных запросов определён стандартами отдельно.
HEAD
Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения. Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая.
POST
Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы.
Важно
В отличие от метода GET, метод POST не считается идемпотентными, то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария).
При результатах выполнения 200 (Ok) и 204 (No Content) в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ 201 (Created) с указанием URI нового ресурса в заголовке Location. Сообщение ответа сервера на выполнение метода POST не кэшируется.
Заголовки протокола HTTP
Заголовок HTTP (HTTP Header) — это строка в HTTP-сообщении, содержащая разделённую двоеточием пару вида «параметр-значение». Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF). Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения (если иное не предусмотрено форматом поля). Пример заголовков ответа сервера:
1Server: Apache/2.2.3 (CentOS)2Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT3Content-Type: text/html; charset=UTF-84Accept-Ranges: bytes5Date: Thu, 03 Mar 2011 04:04:36 GMT6Content-Length: 29457Age: 518X-Cache: HIT from proxy.omgtu9Via: 1.0 proxy.omgtu (squid/3.1.8)10Connection: keep-alive1112200 OK
Тело протокола HTTP
Тело HTTP сообщения (message-body), если оно присутствует, используется для передачи сущности, связанной с запросом или ответом. Тело сообщения (message-body) отличается от тела сущности(entity-body) только в том случае, когда при передаче применяется кодирование, указанное в заголовке Transfer-Encoding. В остальных случаях тело сообщения идентично телу сущности.
Заголовок Transfer-Encoding должен отправляться для указания любого кодирования передачи, примененного приложением в целях гарантирования безопасной и правильной передачи сообщения.
Transfer-Encoding - это свойство сообщения, а не сущности, и оно может быть добавлено или удалено любым приложением в цепочке запросов/ответов. Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения (message-body) может быть добавлено в запрос только когда метод запроса допускает тело объекта (entity-body).
Все ответы содержат тело сообщения, возможно нулевой длины, кроме ответов на запрос методом HEAD и ответов с кодами статуса 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified).
| Код возврата | Описание кода возврата HTTP |
|---|---|
| 100 | Продолжить (Continue) |
| 101 | Переключение протоколов (switching protocols) |
| 200 | OK |
| 201 | Создан (created) |
| 202 | Принят |
| 203 | Неавторитеная информация (non-authoritative information) |
| 204 | Файл пуст (no content) |
| 205 | Сброс содержимого (reset content) |
| 206 | Частичное содержимое (partial content) |
| 300 | Многократный выбор (multiple choices) |
| 301 | Перемещен постоянно (moved permanently) |
| 302 | Перемещен временно (moved temporarily) |
| 303 | Смотри другой (see other) |
| 304 | Неизмененный (not modified) |
| 305 | Использовать прокси-сервер (use proxy) |
| 400 | Неправильный запрос (bad request) |
| 401 | Не авторизирован (unauthorized) |
| 402 | Payment Required |
| 403 | Нет доступа (forbidden) |
| 404 | Не найден |
| 405 | Метод не разрешен (method not allowed) |
| 406 | Неприемлемый (not acceptable) |
| 407 | Требуется аутентификация на прокси-сервере (proxy authentication required) |
| 408 | Превышение тайм-аута запроса (request time-out) |
| 411 | Требуется длина (при использовании метода POST) |
| 412 | Не выполнено предыдущее условие (precondition failed) |
| 413 | Объект запроса слишком велик (request entity too large) |
| 414 | Запрашиваемый URL слишком велик (request URL too large) |
| 415 | Неподдерживаемый тип информации (unsupported media type) |
| 500 | Ошибка сервера (server error) |
| 501 | Не реализован (not implemented) |
| 502 | Неправильный шлюз (Bad Gateway) |
| 503 | Нехватка ресурсов (out of resources) |
| 504 | Превышен тайм-аут шлюза |
| 505 | Неподдерживаемая версия HTTP (HTTP version not supported) |
Чтобы на практике увидеть какие HTTP запросы передает и получает сервер, можно воспользоваться Инструментами разработчика браузера Google Chrome, для этого необходимо выбрать в «Инструменты» - «Инструменты разработчика».
Перейти в открывшемся снизу окне во вкладку «Network». Обновить открытую страницу. В списке слева будут отображены посылаемые браузером HTTP-запросы. Вопрос на получение страницы будет самым первым в списке. Детальную информацию о нем можно получить выбрав его.
HTTPS
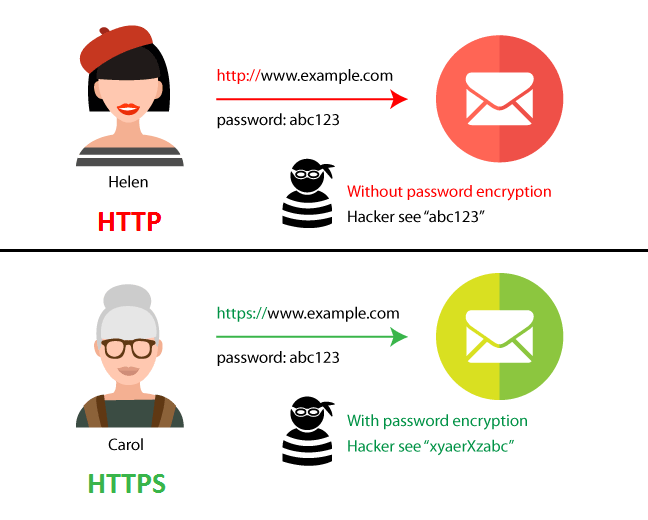
Как данные защищаются? 🤔
Как клиент и сервер могут установить безопасное соединение, если кто-то уже прослушивает их канал? 🤔
Что такое сертификат безопасности и почему я должен кому-то платить, чтобы получить его? 🤔

С вашего собственного компьютера на другие компьютеры вашей локальной сети, через роутеры и свитчи, через вашего провайдера и через множество других промежуточных провайдеров – огромное количество организаций ретранслирует ваши данные. Если злоумышленник окажется хотя бы в одной из них — у него есть возможность посмотреть, какие данные передаются.
Как правило, запросы передаются посредством обычного HTTP, в котором и запрос клиента, и ответ сервера передаются в открытом виде. И есть множество весомых аргументов, почему HTTP не использует шифрование по умолчанию:
- Для этого требуется больше вычислительных мощностей
- Передается больше данных
- Нельзя использовать кеширование
Но в некоторых случаях, когда по каналу связи передается исключительно важная информация (такая как, пароли или данные кредитных карт), необходимо обеспечить дополнительные меры, предотвращающие прослушивание таких соединений
Transport Layer Security (TLS)
Сейчас мы собираемся погрузиться в мир криптографии, но нам не потребуется для этого какого-то особенного опыта — мы рассмотрим только самые общие вопросы. Итак, криптография позволяет защитить соединение от потенциальных злоумышленников, которые хотят воздействовать на соединение или просто прослушивать его.
TLS — наследник SSL — это такой протокол, наиболее часто применяемый для обеспечения безопасного HTTP соединения (так называемого HTTPS). TLS расположен на уровень ниже протокола HTTP в модели OSI. Объясняя на пальцах, это означает, что в процессе выполнения запроса сперва происходят все “вещи”, связанные с TLS-соединением и уже потом, все что связано с HTTP-соединением.
TLS – гибридная криптографическая система. Это означает, что она использует несколько криптографических подходов, которые мы и рассмотрим далее:
1) Асиметричное шифрование (криптосистема с открытым ключом) для генерации общего секретного ключа и аутентификации (то есть удостоверения в том, что вы – тот за кого себя выдаете).
2) Симметричное шифрование, использующее секретный ключ для дальнейшего шифрования запросов и ответов.
👀
Криптосистема с открытым ключом
Криптосистема с открытым ключом – это разновидность криптографической системы, когда у каждой стороны есть и открытый, и закрытый ключ, математически связанные между собой. Открытый ключ используется для шифрования текста сообщения в “тарабарщину”, в то время как закрытый ключ используется для дешифрования и получения исходного текста.
С тех пор как сообщение было зашифровано с помощью открытого ключа, оно может быть расшифровано только соответствующим ему закрытым ключом. Ни один из ключей не может выполнять обе функции. Открытый ключ публикуется в открытом доступе без риска подвергнуть систему угрозам, но закрытый ключ не должен попасть к кому-либо, не имеющему прав на дешифровку данных. Итак, мы имеем ключи – открытый и закрытый. Одним из наиболее впечатляющих достоинств ассиметричного шифрования является то, что две стороны, ранее совершенно не знающие друг друга, могут установить защищенное соединение, изначально обмениваясь данными по открытому, незащищенному соединению. Клиент и сервер используют свои собственные закрытые ключи (каждый – свой) и опубликованный открытый ключ для создания общего секретного ключа на сессию.
Это означает, что если кто-нибудь находится между клиентом и сервером и наблюдает за соединением – он все равно не сможет узнать ни закрытый ключ клиента, ни закрытый ключ сервера, ни секретный ключ сессии.
Как это возможно? Математика!
Одним из наиболее распространенных подходов является алгоритм обмена ключами Ди́ффи — Хе́ллмана (DH). Этот алгоритм позволяет клиенту и серверу договориться по поводу общего секретного ключа, без необходимости передачи секретного ключа по соединению. Таким образом, злоумышленники, прослушивающие канал, не смогу определить секретный ключ, даже если они будут перехватывать все пакеты данных без исключения.
Как только произошел обмен ключами по DH-алгоритму, полученный секретный ключ может использоваться для шифрования дальнейшего соединения в рамках данной сессии, используя намного более простое симметричное шифрование.
Немного математики…
Математические функции, лежащие в основе этого алгоритма, имею важную отличительную особенность — они относительно просто вычисляются в прямом направлении, но практически не вычисляются в обратном. Это именно та область, где в игру вступают очень большие простые числа.
Пусть Алиса и Боб – две стороны, осуществляющие обмен ключами по DH-алгоритму. Сперва они договариваются о некотором основании root (обычно маленьком числе, таком как 2,3 или 5 ) и об очень большом простом числе prime(больше чем 300 цифр). Оба значения пересылаются в открытом виде по каналу связи, без угрозы компрометировать соединение.
Напомним, что и у Алисы, и у Боба есть собственные закрытые ключи (из более чем 100 цифр), которые никогда не передаются по каналам связи.
По каналу связи же передается смесь mixture, полученная из закрытых ключей, а также значений prime и root.
Таким образом:
1Alice’s mixture = (root ^ Alice’s Secret) % prime
1Bob’s mixture = (root ^ Bob’s Secret) % prime
где % — остаток от деления
Таким образом, Алиса создает свою смесь mixture на основе утвержденных значений констант (root и prime), Боб делает то же самое. Как только они получили значения mixture друг друга, они производят дополнительные математические операции для получения закрытого ключа сессии. А именно:
Вычисления Алисы
1(Bob’s mixture ^ Alice’s Secret) % prime
Вычисления Боба
1(Alice’s mixture ^ Bob’s Secret) % prime
Результатом этих операций является одно и то же число, как для Алисы, так и для Боба, и это число и становится закрытым ключом на данную сессию.
Важно
Обратите внимание, что ни одна из сторон не должна была пересылать свой закрытый ключ по каналу связи, и полученный секретный ключ так же не передавался по открытому соединению. Великолепно!

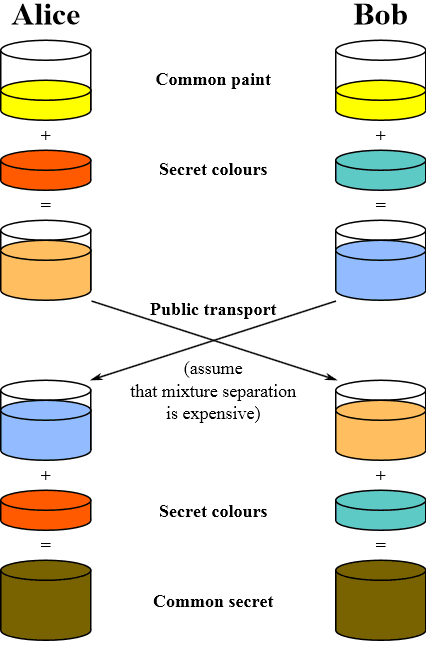
Обратите внимание как начальный цвет (желтый) в итоге превращается в один и тот же “смешанный” цвет и у Боба, и у Алисы. Единственное, что передается по открытому каналу связи так это наполовину смешанные цвета, на самом деле бессмысленные для любого прослушивающего канал связи.
Симметричное шифрование
Обмен ключами происходит всего один раз за сессию, во время установления соединения. Когда стороны уже договорились о секретном ключе, клиент-серверное взаимодействие происходит с помощью симметричного шифрования, которое намного эффективнее для передачи информации, поскольку не требуется дополнительные издержки на подтверждения.
Используя секретный ключ, полученный ранее, а также договорившись по поводу режима шифрования, клиент и сервер могут безопасно обмениваться данными, шифруя и дешифруя сообщения, полученные друг от друга с использованием секретного ключа.
Злоумышленник, подключившийся каналу, будет видеть лишь “мусор”, гуляющий по сети взад-вперед.
Аутентификация
Алгоритм Диффи-Хеллмана позволяет двум сторонам получить закрытый секретный ключ. Но откуда обе стороны могут уверены, что разговаривают действительно друг с другом? Мы еще не говорили об аутентификации.
Для решения проблемы аутентификации, нам нужна Инфраструктура открытых ключей, позволяющая быть уверенным, что субъекты являются теми за кого себя выдают. Эта инфраструктура создана для создания, управления, распространения и отзыва цифровых сертификатов.
Сертификаты
это те раздражающие штуки, за которые нужно платить, чтобы сайт работал по HTTPS.
Но, на самом деле, что это за сертификат, и как он предоставляет нам безопасность?
В самом грубом приближении, цифровой сертификат – это файл, использующий электронной-цифровую подпись (подробнее об этом через минуту) и связывающий открытый (публичный) ключ компьютера с его принадлежностью. Цифровая подпись на сертификате означает, что некто удостоверяет тот факт, что данный открытый ключ принадлежит определенному лицу или организации.
По сути, сертификаты связывают доменные имена с определенным публичным ключом. Это предотвращает возможность того, что злоумышленник предоставит свой публичный ключ, выдавая себя за сервер, к которому обращается клиент.
В примере с телефоном, приведенном выше, хакер может попытаться предъявить мне свой публичный ключ, выдавая себя за моего друга – но подпись на его сертификате не будет принадлежать тому, кому я доверяю.
Чтобы сертификату доверял любой веб-браузер, он должен быть подписан аккредитованным удостоверяющим центром (центром сертификации, Certificate Authority, CA).
CA – это компании, выполняющие ручную проверку, того что лицо, пытающееся получить сертификат, удовлетворяет следующим двум условиям:
- является реально существующим;
- имеет доступ к домену, сертификат для которого оно пытается получить.
Как только CA удостоверяется в том, что заявитель – реальный и он реально контролирует домен, CA подписывает сертификат для этого сайта, по сути, устанавливая штамп подтверждения на том факте, что публичный ключ сайта действительно принадлежит ему и ему можно доверять.
В ваш браузер уже изначально пред загружен список аккредитованных CA. Если сервер возвращает сертификат, не подписанный аккредитованным CA, то появится большое красное предупреждение. В противном случае, каждый мог бы подписывать фиктивные сертификаты.